Continuous Integration and Continuous Delivery are two concepts that come up frequently in modern DevOps. At a high level, continuous integration (CI) describes the processes and tooling used to ensure that software changes can be tested and built in an automated fashion. Continuous delivery (CD) adds to that concept by providing the setup needed for newly built software releases to be deployed to production or development environments.
While logically, CI and CD are distinct processes, practically, they are often combined into a single step. Many organizations will use the same tool—such as Jenkins, GitHub Actions, Gitlab CI, or many others—to build, test, and deploy the new version of their code.
CI/CD is certainly a viable approach, and it’s one we have used many times in the past at FP Complete. However, we’re also aware of some its limitations. Let’s explore some of the weaknesses of this approach.
A combined CI/CD pipeline will end up needing several different permissions, including:
These permissions are typically passed in via secret variables to the CI system. By combining CI/CD into a single process, we essentially require that any users with maintainer access to the job get access to all these abilities. Furthermore, if a nefarious (or faulty) code change is merged into source code that reveals secret variables from CI, production cluster tokens may be revealed.
Following the principle of least privilege, reducing a CI system’s access is preferable.
Baking CD into the primary CI job of an application means that any cluster that wants to run that application needs to modify the originating CI job. In many cases, this isn’t a blocker. There’s a source repository with the application code, and the application runs on just one cluster in one production environment. Hard-coding information into the primary CI job about that one cluster and environment feels natural.
But not all software works like this. Providing CI, QA, staging, and production environments is one common obstacle. Does the CI job update all these environments on each commit? Is there unique mapping from different branches to different environments?
Multi-cloud or multi-region deployment take this concept further. If your application needs to be geolocated, configuring the originating CI job to update all the different clouds and regions can be a burden.
Continuing this theme is the presence of upstream software. If you’re deploying an open-source application or vendor-provided software, you likely have no direct control of their CI job. And modifying that job to trigger a deployment within your cluster is likely not an option — not to mention a security nightmare.
Tying up the story is cluster credentials. As part of normal cluster maintenance, you will likely rotate credentials for cluster access. This is a good security practice in general and maybe absolutely required when performing certain kinds of updates. When you have dozens of applications on several different CI systems, each with its own set of cluster credentials hardcoded into CI secret variables, such rotations become onerous.
Instead, with Kube360, we decided to go the route of minimizing the role of Continuous Integration to:
This addresses the four concerns above:
But it still begs the question: how do we handle Continuous Deployment in Kube360?
Kube360 ships with ArgoCD out of the box. ArgoCD provides in-cluster Continuous Deployment. It relies on a GitOps workflow. Each deployed application tracks a Git repository, which defines the Kubernetes manifest files. These manifest files contain a fully declarative statement of how to deploy an application, including which version of the Docker image to deploy. This provides centralized definitions of your software stack and the audibility and provenance of deployments through Git history.
This has some apparent downsides. Deploying new versions of software is now a multi-step process, including updating the source code, waiting for CI, updating the Git repository, and then updating ArgoCD. You must now maintain multiple copies of manifest files for different clusters and different environments.
With careful planning, all of these can be overcome. And as you’ll see below, some of these downsides can be a benefit for some industries.
In our recommended setup, we strongly leverage overlays for creating modifications of application deployments. Instead of duplicating your manifest files, you take a base set of manifests and apply overlays for different clusters or different environments. This cuts down on repetition and helps ensure that your QA and staging environments are accurately testing what you deploy to production.
Each deployment can choose to either enable or disable auto-sync. With auto-sync enabled, each push to the manifest file Git repository will automatically update the code running in production. When disabled, the central dashboard will indicate which applications are fully synchronized and lagging the Git repository of manifest files.
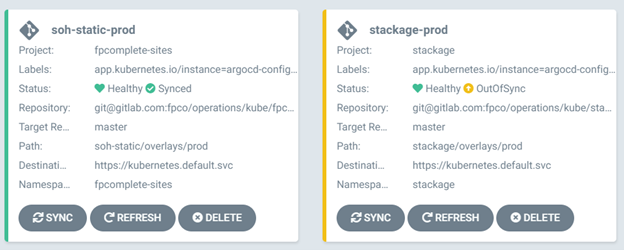
Which option you choose depends upon your security and regulatory concerns. Development environments typically enable auto-sync for ease of testing. In some cases, auto-sync makes perfect sense for production; you may want to strongly limit the permissions model around updating a production deployment and make the final deploy step the responsibility of a quality auditor.
An advantage of the GitOps workflow is that each update to the deployment is accompanied by a Git commit reflecting the new version of the Docker image. A downside is that this requires an explicit action by an engineer to create this commit. In some cases, it’s desirable to automatically update the manifest repository each time a new Docker image is available.
To allow for this, FP Complete has developed a tool for automatic management of these Git repositories, providing fast updates without an operator’s involvement. When paired with auto sync, this can provide for a fully automated deployment process on each commit to a source repository. But by keeping this as an optional component, you retain full flexibility to create a pipeline in line with your goals and security needs.
Permissions for modifying your cluster always stay within your cluster. You no longer need to distribute Kubernetes tokens to external CI systems. Within the cluster, Kube360 grants ArgoCD access to update deployments. When deploying to a new cluster, no update of Kubernetes configuration is needed. Once you copy over Docker registry tokens, you can read in the Docker images and deploy directly into the local cluster.
At FP Complete, we believe it is vital to balance developer productivity and quality guarantees. One of the best ways to optimize this balance is to leverage great tools to improve both productivity and quality simultaneously. With Kube360, we’ve leveraged best-in-class tooling with innovative best practices to provide a simple, secure, and productive build and deploy pipeline. To learn more, check out our free video demo!

Subscribe to our blog via email
Email subscriptions come from our Atom feed and are handled by Blogtrottr. You will only receive notifications of blog posts, and can unsubscribe any time.