FP Complete Corporation, headquartered in Charlotte, North Carolina, is a global technology company building next-generation software to solve complex problems. We specialize in Server-Side Software Engineering, DevSecOps, Cloud-Native Computing, Distributed Ledger, and Advanced Programming Languages. We have been a full-stack technology partner in business for 10+ years, delivering reliable, repeatable, and highly secure software. Our team of engineers, strategically located in over 13 countries, offers our clients one-stop advanced software engineering no matter their size.
For the past few months, the FP Complete engineering team has been working with Levana Protocol on a DeFi platform for leveraged assets on the Terra blockchain. But more recently, we’ve additionally been helping launch the Levana Dragons meteor shower. This NFT launch completed in the middle of last week, and to date is the largest single NFT event in the Terra ecosystem. We were very excited to be a part of this. You can read more about the NFT launch itself on the Levana Protocol blog post.
We received a lot of positive feedback about the smoothness of this launch, which was pretty wonderful feedback to hear. People expressed interest in learning about the technical decisions we made that led to such a smooth event. We also had a few hiccups occur during the launch and post-launch that are worth addressing as well.
So strap in for a journey involving cloud technologies, DevOps practices, Rust, React, and—of course—Dragons.
The Levana Dragons meteor shower was an event consisting of 44 separate “showers”, or drops during which NFT meteors would be issued. Participants in a shower competed by contributing UST (a Terra-specific stablecoin tied to US Dollars) to a specific Terra wallet. Contributions from a single wallet across the shower were aggregated into a single contribution, and contributions of a higher amount resulted in a better meteor. At the least granular level, this meant stratification into legendary, ancient, rare, and common meteors. But higher contributions also lead to the greater likelihood of receiving an egg inside your meteor.
Each shower was separated from the next by 1 hour, and we opened up the site about 24 hours before the first shower occurred. That means the site was active for contributions for about 67 hours straight. Then, following the showers, we needed to mint the actual NFTs, ship them to users’ wallets, and open up the “cave” page where users could view their NFTs.
So all told, this was an event that spanned many days, had lots of bouts of high activity, was involved in a game that incorporated many financial transactions, and any downtime, slowness, or poor behavior could result in user frustration or worse. On top of that, given the short timeframe this event was intended to be active, attacks such as DDoS taking down the site could be catastrophic for success of the showers. And the absolute worst case would be a compromise allowing an attacker to redirect funds to a different wallet.
All that said, let’s dive in.
A major component of the meteor drop was to track contributions to the destination wallet, and provide high level data back to users about these activities. This kind of high level data included the floor prices per shower, the timestamps of the upcoming drops, total meteors a user had acquired so far, and more. All this information is publicly available on the blockchain, and in principle could have been written as frontend logic. However, the overhead of having every visitor to the site downloading essentially the entire history of transactions with the destination wallet would have made the site unusable.
Instead, we implemented a backend web server. We used Rust (with Axum) for this for multiple reasons:
The server was responsible for keeping track of configuration data (like the shower timestamps and destination wallet address), downloading transaction information from the blockchain (using the Full Client Daemon), and answering queries to the frontend (described next) providing this information.
We could have kept data in a mutable database like PostgreSQL, but instead we decided to keep all data in memory and download from scratch from the blockchain on each application load. Given the size of the data, these two decisions initially seemed very wise. We’ll see some outcomes of this when we analyze performance and look at some of our mistakes below.
The primary interface users interacted with was a standard React frontend application. We used TypeScript, but otherwise stuck with generic tools and libraries wherever possible. We didn’t end up using any state management libraries or custom CSS systems. Another thing to note is that this frontend is going to expand and evolve over time to include additional functionality around the evolving NFT concept, some of which has already happened, and we’ll discuss below.
One specific item that popped up was mobile optimization. Initially, the plan was for the meteor shower site to be desktop-only. After a few beta runs, it became apparent that the majority of users were using mobile devices. As a DAO, a primary goal of Levana is to allow for distributed governance of all products and services, and therefore we felt it vital to be responsive to this community request. Redesigning the interface for mobile and then rewriting the relevant HTML and CSS took up a decent chunk of time.
Many DApps sites are exclusively client side, leveraging frontend logic interacting with the blockchain and smart contracts exclusively. For these kinds of sites, hosting options like Vercel work out very nicely. However, as described above, this application was a combo frontend/backend. Instead of splitting the hosting between two different options, we decided to host both the static frontend app and the backend dynamic app in a single place.
At FP Complete, we typically use Kubernetes for this kind of deployment. In this case, however, we went with Amazon ECS. This isn’t a terribly large delta from our standard Kubernetes deployments, following many of the same patterns: container-based application, rolling deployments with health checks, autoscaling and load balancers, externalized TLS cert management, and centralized monitoring and logging. No major issues there.
Additionally, to help reduce burden on the backend application and provide a better global experience for the site, we put Amazon CloudFront in front of the application, which allowed caching the static files in data centers around the world.
Finally, we codified all of this infrastructure using Terraform, our standard tool for Infrastructure as Code.
GitLab is a standard part of our FP Complete toolchain. We leverage it for internal projects for its code hosting, issue tracking, Docker registry, and CI integration. While we will often adapt our tools to match our client needs, in this case we ended up using our standard tool, and things went very well.
We ended up with a four-stage CI build process:
clippy and fmt), producing an artifact with the single file compiled binarySteps (3) and (4) are set up to only run on the master and prod branches. This kind of automated deployment setup made it easy for our distributed team to get changes into a real environment for review quickly. However, it also opened a security hole we needed to address.
Due to the nature of this application, any kind of downtime during the active showers could have resulted in a lot of egg on our faces and a missed opportunity for the NFT raise. However, there was a far scarier potential outcome. Changing a single config value in production—the destination wallet—would have enabled a nefarious actor to siphon away funds intended for NFTs. This was the primary concern we had during the launch.
We considered multiple social engineering approaches to the problem, such as advertising to potentially users the correct wallet address they should be using. However, we decided that most likely users would not be checking addresses before sending their funds. We did set up some emergency “shower halted” page and put in place an on-call team to detect and deploy such measures if necessary, but fortunately nothing along those lines occurred.
However, during the meteor shower, we did instate an AWS account lockdown. This included:
We additionally vetted all other components in the pipeline of DNS resolution, such as domain name registrar, Route 53, and other AWS services for hosting.
These are generally good practices, and over time we intend to refine the AWS permissions setup for Levana’s AWS account in general. However, this launch was the first time we needed to use AWS for app deployment, and time did not permit a thorough AWS permissions analysis and configuration.
As I just mentioned, during the shower we had an on-call team ready to jump into action and a playbook to address potential issues. Issues essentially fell into three categories:
The FP Complete team were responsible for observing (1) and (2). I’ll be honest that this is not our strong suit. We are a team that typically builds backends and designs DevOps solutions, not an on-call operations team. However, we were the experts in both the DevOps hosting, as well as the app itself. Fortunately, no major issues popped up, and the on-call team got to sit on their hands the whole time.
Out of a preponderance of caution, we did take a few extra steps before the showers started to try and ensure we were ready for any attack:
In all of our load testing pre-launch, we had seen that 512 CPU units was sufficient to handle 100,000 requests per second per instance with 99th percentile latency of 3.78ms. With these bumped limits in production, and in the middle of the highest activity on the site, we were very pleased to see the following CPU and memory usage graphs:
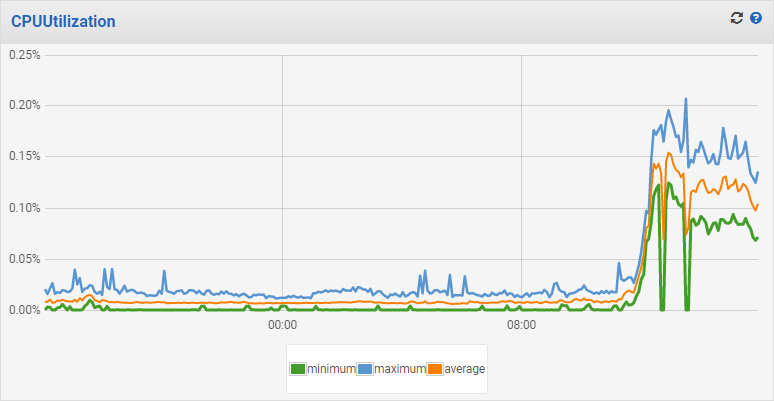
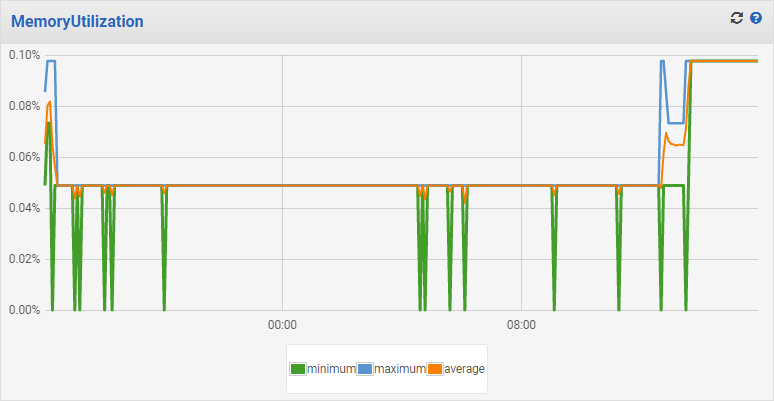
This was a nice testament to the power of a Rust-written web service, combined with proper autoscaling and CloudFront caching.
Alright, let’s put the app itself to the side for a second. We knew that, at the end of the shower, we would need to quickly mint NFTs for everyone wallet that donated more than $8 during a single shower. There are a few problems with this:
What we ended up doing was writing a Python script that pregenerated 100,000 or so meteor images. We did this generation directly on an Amazon EC2 instance. Then, instead of uploading the images to an IPFS hosting/pinning service, we ran the IPFS daemon directly on this EC2 instance. We additionally backed up all the images on S3 for redundant storage. Then we launched a second EC2 instance for redundant IPFS hosting.
This Python script not only generated the images, but also generated a CSV file mapping the image Content ID (IPFS address) together with various pieces of metadata about the meteor image, such as the meteor body. We’ll use this CID/meteor image metadata mapping for correct minting next.
All in all, this worked just fine. However, there were some hurdles getting there, and we have plans to change this going forward in future stages of the NFT evolution. We’ll mention those below.
Once the shower finished, we needed to get NFTs into user wallets as quickly as possible. That meant we needed two different things:
The former was handled by the previous step. The latter was additional pieces of Rust tooling we wrote that leveraged the same internal libraries we wrote for the backend application. The purpose of this tooling was to:
This process produced a few different pieces of data:
This final point is also influencing the design of the next few stages of this project. Specifically, while a smart contract would be the more natural way to interact with NFTs in general, we cannot expose the meteor/egg mapping on the blockchain. Therefore, the “cracking” phase (which will allow users to exchange meteors for their potential eggs) will need to work with another backend application.
In any event, this metadata-generation process was something we tested multiple times on data from our beta runs, and were ready to produce and send over to Knowhere.art for minting soon after the shower. I believe users got NFTs in their wallets within 8 hours of the end of the shower, which was a pretty good timeframe overall.
The final step was opening the cave, a new page on the meteor site that allows users to view their meteors. This phase was achieved by updating the configuration values of the backend to include:
Once we switched the config values, the cave opened up, and users were able to access it. Besides pulling the static information mentioned above from the server, all cave page interactions occur fully client side, with the client querying the blockchain using the Terra.js library.
And that’s where we’re at today. The showers completed, users got their meteors, the cave is open, and we’re back to work on implementing the cracking phase of this project. W00t!
Overall, this project went pretty smoothly in production. However, there were a few gotcha moments worth mentioning.
The biggest issue we hit during the showers, and the one that had the biggest potential to break everything, was FCD rate limiting. We’d done extensive testing prior to the real showers on testnet, with many volunteer testers in addition to bots. We never ran into a single example that I’m aware of where rate limiting kicked in.
However, the real production shower run into such rate limiting issues about 10 showers into the event. (We’ll look at how they manifested in a moment.) There are multiple potentially contributing factors for this:
Whatever the case, we began to notice the rate limiting when we tried to roll out a new feature. We implemented the Telescope functionality, which allowed users to see the historical floor prices in previous showers.
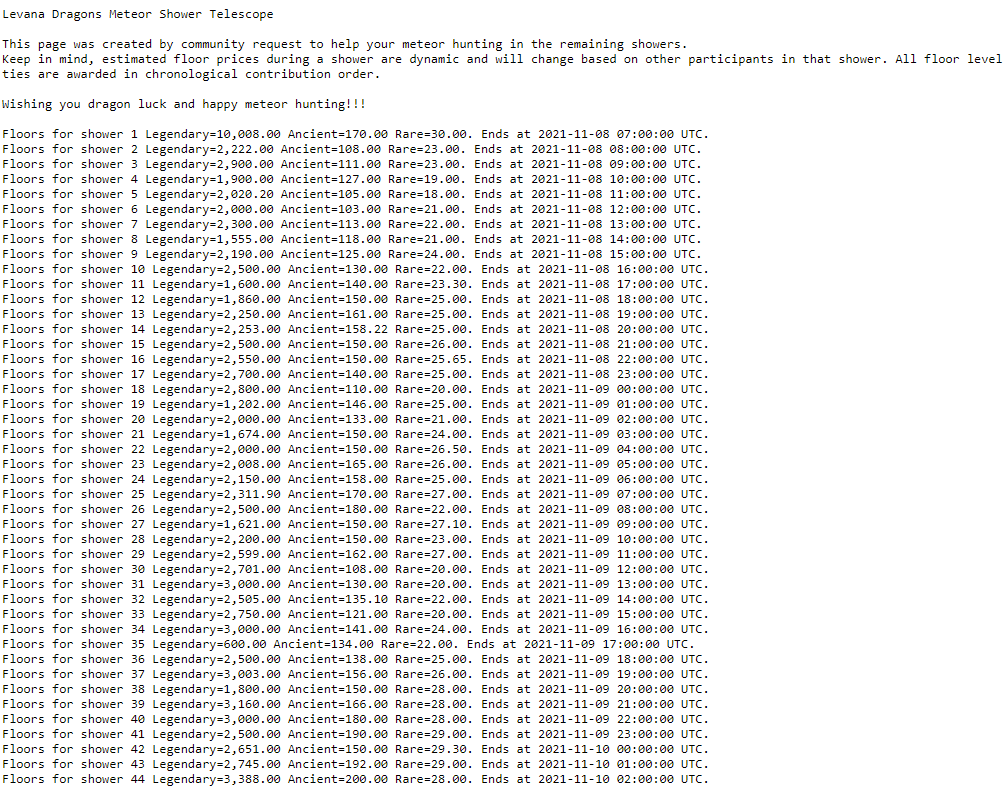
After pushing the change to ECS, however, we noticed that the new deployment didn’t go live. The reason was that, during the initial data load process, the new processes were receiving rate limiting responses and dying. We tried fixing this by adding a delay or other kinds of retry logic. However, none of these combinations allowed the application to begin processing requests within ECS’s readiness check period. (We could have simply turned off health checks, but that would have opened a new can of worms.)
This problem was fairly critical. Not being able to roll out new features or bug fixes was worrying. But more troubling was the lack of autohealing. The existing instances continued to run fine, because they only needed to download small amounts of data from FCD to stay up-to-date, and therefore never triggered the rate limiting. But if any of those instances went down, ECS wouldn’t be able to replace them with healthy instances.
Fortunately, we had already written the majority of a caching solution in prior weeks, and had not finished the work because we thought it wasn’t a priority. After a few hair-raising hours of effort, we got a solution in place which:
This reduced startup time significantly, bypassed the rate limiting completely, and allowed us to roll out new features and not worry about the entire site going down.
FP Complete’s DevOps approach is decidedly cloud-focused. For large blob storage, our go-to solution is almost always cloud-based blob storage, which would be S3 in the case of Amazon. We had zero experience with large scale IPFS data hosting prior to this project, which presented a unique challenge.
As mentioned, we didn’t want to go with one of the IPFS pinning services, since the rate limiting may have prevented us from uploading all the pregenerated images. (Rate limiting is beginning to sound like a pattern here…) Being comfortable with S3, we initially tried hosting the images using go-ds-s3, a plugin for the ipfs CLI that uses S3 for storage. We still don’t know why, but this never worked correctly for us. Instead, we reverted to storing the raw image data on Amazon EBS, which is more expensive and less durable, but actually worked. To fix the durability issue, we backed up all the raw image files to S3.
Overall, however, we’re not happy with this outcome. The cost for this hosting is relatively high, and we haven’t set up a truly fault-tolerant, highly available hosting. At this point, we would like to switch over to an IPFS pinning service, such as Pinata. Now that the images are available on IPFS, issuing API calls to pin those files should be easier than uploading the complete images. We’re planning on using this as a framework going forward for other images, namely:
ipfs locally to make the images available on IPFSThe next issue we ran into was… RATE LIMITING, again. This time, we discovered that Cloudflare’s IPFS gateway was rate limiting users on downloading their meteor images, resulting in a situation where users would see only some of their meteors appear in their cave page. We solved this one by sticking CloudFront in front of the S3 bucket holding the meteor images and serving from there instead.
Going forward, when it’s available, Cloudflare R2 is a promising alternative to the S3+CloudFront offering, due to reduced storage cost and entirely removed bandwidth costs.
This project was a great mix of leveraging existing expertise and pairing with some new challenges. Some of the top lessons we learned here were:
We’re very excited to have been part of such a successful event as the Levana Dragons NFT meteor shower. This was a fun site to work on, with a huge and active user base, and some interesting challenges. It was great to pair together some of our standard cloud DevOps practices with blockchain and smart contract common practices. And using Rust brought some great advantages we’re quite happy with.
Going forward, we’re looking forward to getting to continue evolving the backend, frontend, and DevOps of this project, just like the NFTs themselves will be evolving. Happy dragon luck to all!
Interested in learning more? Check out these relevant articles
Does this kind of work sound interesting? Consider applying to work at FP Complete.
Subscribe to our blog via email
Email subscriptions come from our Atom feed and are handled by Blogtrottr. You will only receive notifications of blog posts, and can unsubscribe any time.