A couple months ago, Michael Snoyman wrote a blogpost
describing an experiment in an efficient implementation of binary
serialization. Since then, we’ve developed this approach into a new
package for efficient serialization of Haskell datatypes. I’m happy
to announce that today we are putting out the initial release of
our new new
store package!
The store package takes a different approach than
most prior serialization packages, in that performance is
prioritized over other concerns. In particular, we do not make many
guarantees about binary compatibility, and instead favor machine
representations. For example, the binary and
cereal packages use big endian encodings for numbers,
whereas x86 machines use little endian. This means that to encode +
decode numbers on an x86 machine, those packages end up swapping
all of the individual bytes around twice!
To serialize a value, store first computes its size
and allocates a properly sized ByteString. This keeps
the serialization logic simple and fast, rather than mixing in
logic to allocate new buffers. For datatypes that need to visit
many values to compute their size, this can be inefficient – the
datatype is traversed once to compute the size and once to do the
serialization. However, for datatypes with constant size, or
vectors of datatypes with constant size, it is possible to very
quickly compute the total required size. List / set / map-like
Store instances all implement this optimization when
their elements have constant size.
store comes with instances for most datatypes from
base, vector, bytestring,
text, containers, and time.
You can also use either GHC generics or Template Haskell to derive
efficient instances for your datatypes.
I updated the serial-bench with
store. Happily, store is even faster than
any of the implementations we had in the benchmark.
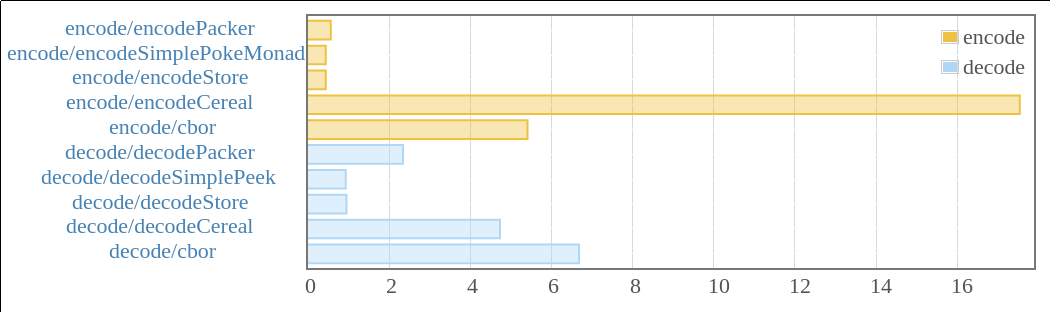
See the detailed report
here. Note that the x-axis is measured in micro-seconds taken
to serialize a 100 element Vector where each element
occupies at least 17 bytes. store is actually
performing this operations in the sub-microseconds (431ns to
encode, 906ns to decode). The results for binary have
been omitted from this graph as it blows out the x-axis scale,
taking around 8 times longer than cereal, nearly 100x
slower than store)
We could actually write a benchmark even more favorable to
store, if we used storable or unboxed vectors! In that
case, store essentially implements a
memcpy.
Now, the benchmark is biased towards the usecase we are
concerned with – serializing a Vector of a small
datatype which always takes up the same amount of space.
store was designed with this variety of usecase in
mind, so naturally it excels in this benchmark. But lets say we
choose a case that isn’t exactly store‘s strongsuit,
how well does it perform? In our experiments, it seems that
store does a darn good job of that too!
The development version of stack now uses
store for serializing caches of info needed by the
build.
With store (~0.082 seconds):
2016-05-23 19:52:06.964518: [debug] Trying to decode /home/mgsloan/.stack/indices/Hackage/00-index.cache @(stack_I9M2eJwnG6d3686aQ2OkVk:Data.Store.VersionTagged src/Data/Store/VersionTagged.hs:49:5)
2016-05-23 19:52:07.046851: [debug] Success decoding /home/mgsloan/.stack/indices/Hackage/00-index.cache @(stack_I9M2eJwnG6d3686aQ2OkVk:Data.Store.VersionTagged src/Data/Store/VersionTagged.hs:58:13)
21210280 bytes
With binary (~0.197 seconds):
2016-05-23 20:22:29.855724: [debug] Trying to decode /home/mgsloan/.stack/indices/Hackage/00-index.cache @(stack_4Jm00qpelFc1pPl4KgrPav:Data.Binary.VersionTagged src/Data/Binary/VersionTagged.hs:55:5)
2016-05-23 20:22:30.053367: [debug] Success decoding /home/mgsloan/.stack/indices/Hackage/00-index.cache @(stack_4Jm00qpelFc1pPl4KgrPav:Data.Binary.VersionTagged src/Data/Binary/VersionTagged.hs:64:13)
20491950 bytes
So this part of stack is now twice as fast!
Beyond the core of store‘s functionality, this
initial release also provides:
Data.Store.Streaming – functions for using
Store for streaming serialization with conduit.
This makes it so that you don’t need to have everything in memory
at once when serializing / deserializing. For applications
involving lots of data, this can essential to having reasonable
performance, or even functioning at all.
This allows us to recoup the benefits of lazy serialization, without paying for the overhead when we don’t need it. This approach is also more explicit / manual with regards to the laziness – the user must determine how their data will be streamed into chunks.
Data.Store.TypeHash, which provides utilities for
computing hashes based on the structural definitions of datatypes.
The purpose of this is to provide a mechanism for tagging
serialized data in such a way that deserialization issues can be
anticipated.
This is included in the store package for a couple
reasons:
It is quite handy to include these hashes with your encoded datatypes. The assumption is that any structural differences are likely to correspond with serialization incompatibilities. This is particularly true when the generics / TH deriving is used rather than custom instances.
It uses store on Template Haskell types in order to
compute a ByteString. This allows us to directly use cryptographic
hashes from the cryptohash package to get a hash of
the type info.
Data.Store.TH not only provides a means to derive
Store instances for your datatypes, but it also
provides utilities for checking them via smallcheck and
hspec. This
makes it easy to check that all of your datatypes do indeed
serialize properly.
These extras were the more recently added parts of
store, and so are likely to change quite a bit from
the current API. The entirety of store is quite new,
and so is also subject to API change while it stabilizes. That
said, we encourage you to give it a try for your application!
Usually, we directly use Storable instances to
implement Store. In functionality,
Storable is very similar to Store. The
key difference is that Store instances can take up a
variable amount of size, whereas Storable types must
use a constant number of bytes. The store package also provides the
convenience of Peek and Poke monads, so
defining custom Store instances is quite a bit more
convenient
Data.Store.TH.Internal defines a function
deriveManyStoreFromStorable, which does the
following:
Store instancesStorable instances.Store instances for all
Storable instancesIn the future, store will likely provide such a
function for users, which restricts it to only deriving
Store instances for types in the current package or
current module. For now, this is just internal convenience.
I noticed that the Storable instance for Bool is a
bit wasteful with its bytes. Rather inexplicably, perhaps due to
alignment concerns, it takes up a whopping 4 bytes to represent a
single bit of info:
instance Storable Bool where sizeOf _ = sizeOf (undefined::HTYPE_INT) alignment _ = alignment (undefined::HTYPE_INT) peekElemOff p i = liftM (/= (0::HTYPE_INT)) $ peekElemOff (castPtr p) i pokeElemOff p i x = pokeElemOff (castPtr p) i (if x then 1 else 0::HTYPE_INT)
We’d prefer to just use a single byte. Since
deriveManyStoreFromStorable skips types that already
have Store instances, all I needed to do was define
our own instance for Bool. To do this, I used the
derive function from the new th-utilities
package (blogpost pending!), to define an instance for
Bool:
$($(derive [d| instance Deriving (Store Bool) |]))
This is a bit of a magical incantation – it runs code at
compiletime which generates an efficient instance Store Bool
where .... We could also use generic deriving, and rely on
the method defaults to just write instance Store Bool.
However, this can be less efficient, because the generics instances
will yield a VarSize for its size,
whereas the TH instance is smart enough to yield
ConstSize. In practice, this is the difference between
having an O(1) implementation for size :: Size
(Vector MyADT), and having an O(n)
implementation. The O(1) implementation just
multiplies the element size by the length, whereas the
O(n) implementation needs to ask each element for its
size.
Subscribe to our blog via email
Email subscriptions come from our Atom feed and are handled by Blogtrottr. You will only receive notifications of blog posts, and can unsubscribe any time.